From Noise to Knowledge: Rethinking Benchmarks for the Early Training of LLMs
Join us in building benchmarks that capture early-stage reasoning & scientific knowledge in LLMs
Register here to participate
- Competition registration: You can register here.
- Discord: You can join the discussion channel here
- Arxiv: You can find more details in the Competition Proposal Paper
Competition Overview
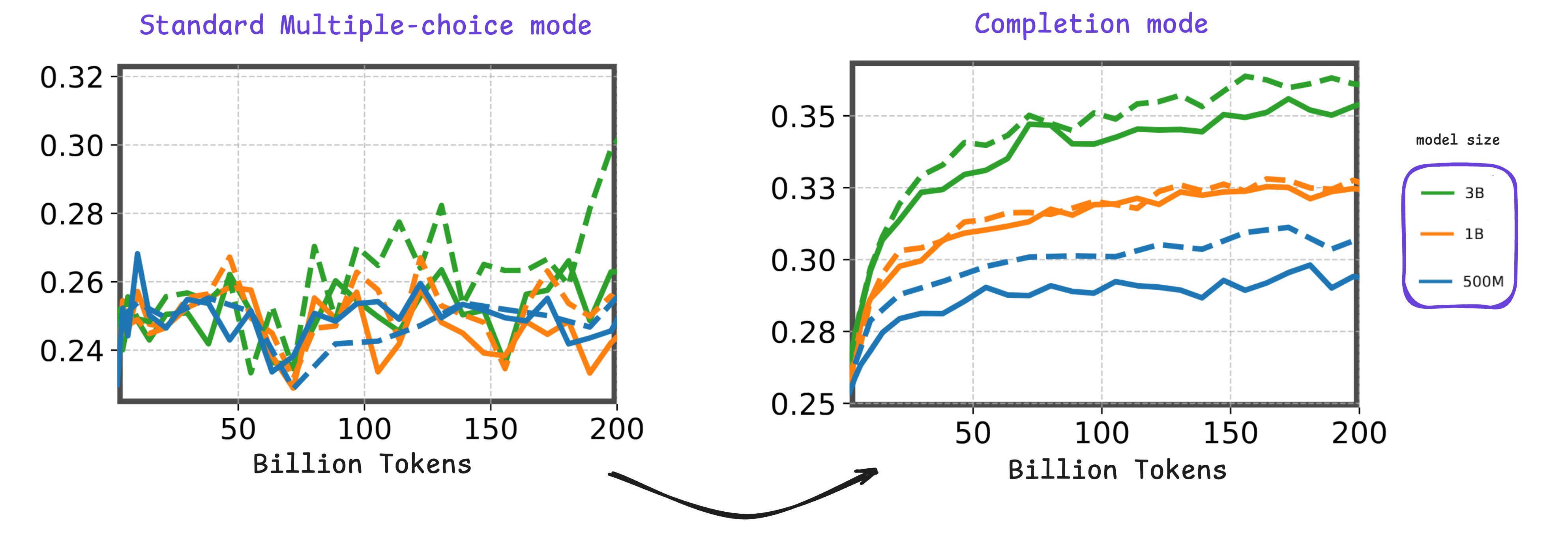
The development of Large Language Models (LLMs) typically begins with a series of ablation experiments, wherein various model architectures, data mixtures, and training hyperparameters are systematically evaluated. This phase is commonly referred to as the early stages of training. During this period, researchers primarily monitor two key metrics: the training loss curve and evaluation scores. However, existing evaluation benchmarks often fail to provide meaningful or discriminative signals during these initial stages where LLMs are trained on a few tokens ~300B tokens, making it challenging to derive conclusive insights from ongoing experiments.
This competition tackles the challenge of designing scientific knowledge evaluation tasks specifically tailored for measuring early training progress of language models. Participants are invited to develop novel evaluation methodologies or adapt existing benchmarks to better capture performance differences among language models. To support this effort, we provide three pre-trained small models (0.5B, 1B, and 3B parameters), along with intermediate checkpoints sampled during training up to 200B tokens. All experiments and development work can be run on widely available free cloud-based GPU platforms, making participation accessible to researchers with modest hardware. Submissions will be evaluated based on three criteria: the quality of the performance signal they produce, the consistency of model rankings at 1 trillion tokens of training, and their alignment with the scientific knowledge domain. By promoting the design of tailored evaluation strategies for SLMs, this competition aims to attract a broad range of participants from around the world, including those who may not be machine learning experts or have access to dedicated GPU resources. Ultimately, this initiative seeks to make foundational LLM research more systematic and benchmark-informed from the earliest phases of model development.
Competition Timeline
| Competition kick-off | 14 July 2025 |
| Warm-up Phase | 14 July 2025 - 24 August 2025 (5 weeks) |
| Development Phase | 25 August 2025 - 2 November 2025 (10 weeks) |
| Final Phase | 3 November 2025 - 10 November 2025 (1 week) |
| Results Announcement | 10 November 2025 |
| Winners' Fact Sheets & Code Release Due | 22 November 2025 |
| NeurIPS Competition Workshop Presentation | 7 December 2025 |
Prizes
- 🥇 1st Place: 6,000 USD
- 🥈 2nd Place: 4,000 USD
- 🥉 3rd Place: 2,000 USD
A public leaderboard showcasing the top evaluation tasks across a diverse set of LLMs will be maintained.
Special prizes
- 🎓 Student Awards: 2x 2,000 USD for the top 2 solutions submitted by participants justifying a student status
Contact and Support
For inquiries and support, reach out to the task coordinators at e2lmc@tii.ae
Organizers
- Mouadh Yagoubi, Technology Innovation Institute
- Yasser Dahou, Technology Innovation Institute
- Billel Mokeddem, Technology Innovation Institute
- Younes Belkada, Technology Innovation Institute
- Phuc H. Le-Khac, Technology Innovation Institute
- Basma El Amel Boussaha, Technology Innovation Institute
- Reda Alami, Technology Innovation Institute
- Jingwei Zuo, Technology Innovation Institute
- Damiano Marsili, California Institute of Technology
- Mugariya Farooq, Technology Innovation Institute
- Mounia Lalmas, Spotify UK
- Georgia Gkioxari, California Institute of Technology
- Patrick Gallinari, Sorbonne University
- Philip Torr, Oxford University
- Hakim Hacid, Technology Innovation Institute
Affiliated Institutions
|
|
|
|
|
|